字节码增强技术,作为Java程序员来说,是个既熟悉又陌生的词,熟悉的是几乎我们无时无刻不再使用着字节码增强技术,陌生则是因为对于开发人员尤其是业务开发来说,实在是没有机会或需求要用到字节码增强相关的技术手段。为此,本文通过简单的介绍来揭开字节码增强技术的神秘面纱,简化起见,本文不对相关技术工具进行深入的介绍,只做综述性质的介绍,旨在让读者有个宏观的认识从而减少初入门时查多方资料的辛苦。
(名词解释: 字节码增强,英文是Bytecode Instrumentation, 那如何理解单词Instrumentation?(本人对这个单词迷惑了很久后,终于有了自己的理解:)) 从词根instrument看,instrument名词形态是工具、器械,动词形态是给什么装上器械,那么instrumentation可以理解为instrument动词形态的名词形式,也就是装上器械、工具,可以理解为要起飞了,所以中文翻译成增强还是很贴切的。)
技术分类
前面也提到了,我们在开发过程中,无时无刻的使用着字节码增强技术,例如简化代码的Lombok,最常用的AOP技术以及各类框架类工具,如代码覆盖率Jacoco、链路追踪的Skywalking、性能分析工具Arthas等等。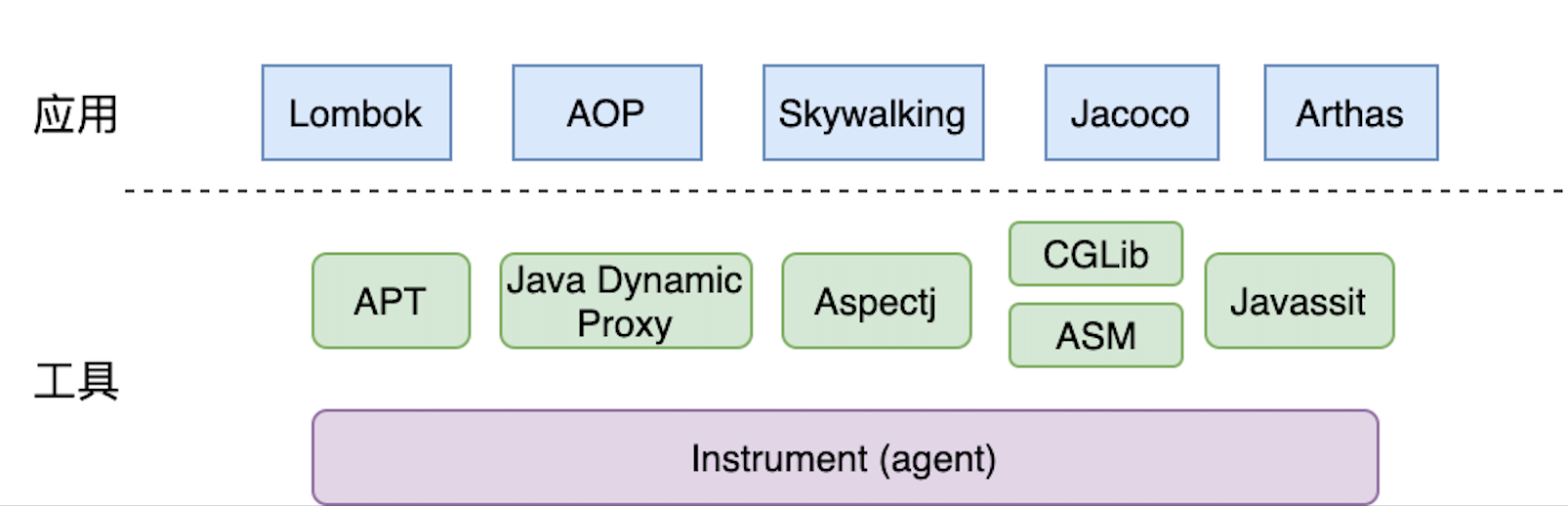
虽然这些工具都统称用到了字节码增强技术,然而其实用到的技术都各有差异,为此我们对不同工具的用途与使用时机进行一次全面的梳理。
从狭义来讲,字节码增强讲的就是对已经是字节码的class文件进行操作,那么主要有两种工具,一个是ASM,另一个是Javassit,ASM是纯粹的对字节码按照java的规范就行字节码理解范畴内的进行修改操作,可以说门槛很高; Javassit则可以理解为是一个提供了对字节码操作API的框架,来简化字节码操作的门槛,让字节码操作像面向对象编程一样简单;因此,由想而知,ASM要比Javassit性能要好,为此,为了鱼和熊掌兼得,我们从ASM基础上又衍生出了CGLib,虽然功能没有ASM强悍,但使用相对简单了很多。
那么从广义上来讲,所有让代码具备原本不具有的功能,那种类似魔法效果的技术,都统称为字节码增强。
从字节码生命周期看,除了字节码class文件外,还包括从源代码生成字节码的过程,以及字节码进入运行时后classloader加载前,以及加载后的运行。
正如AOP技术可以分为静态织入和动态织入(参见会用就行了?你知道 AOP 框架的原理吗?),字节码也可以分为编译前、编译后、加载前、加载后几个阶段。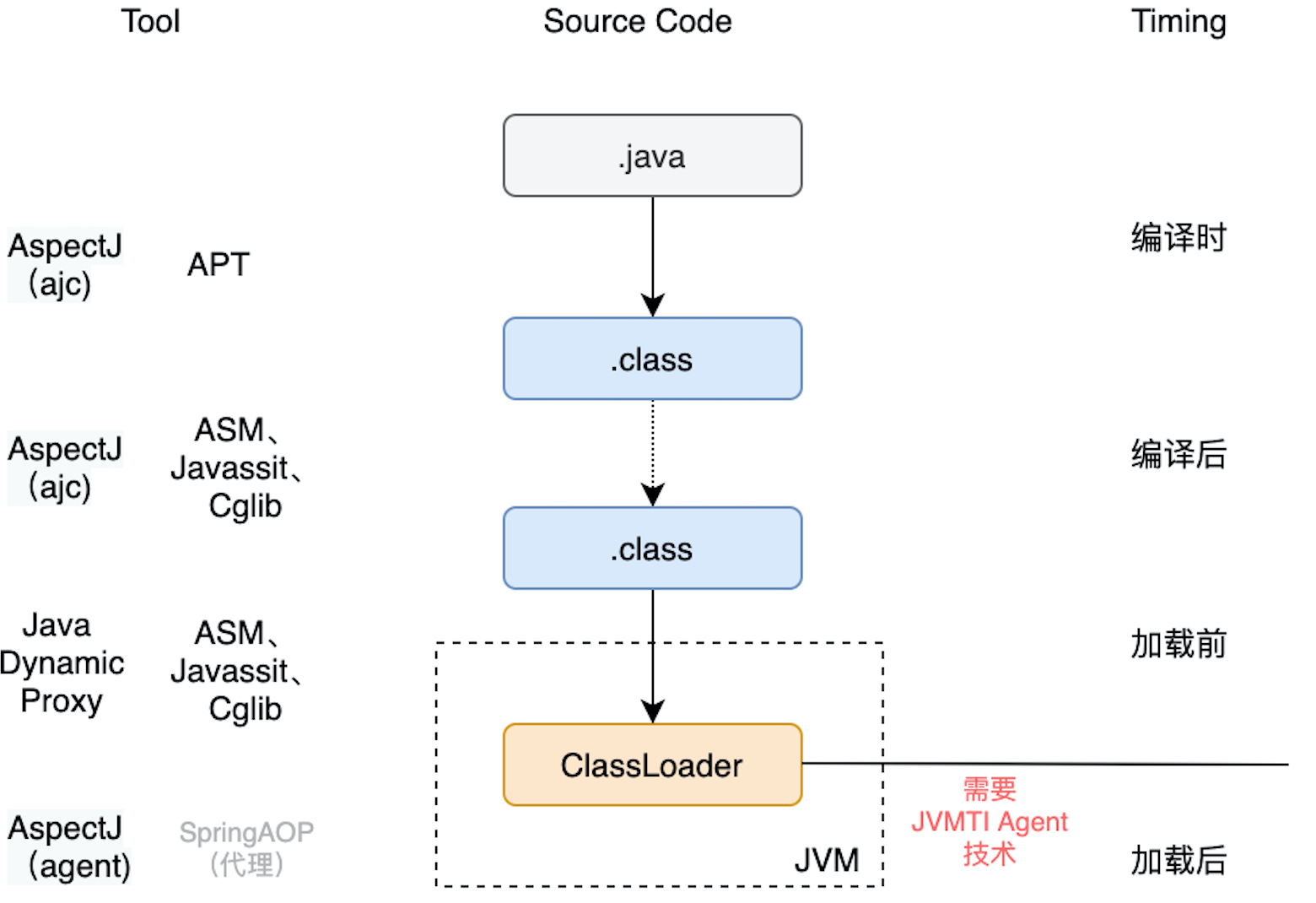
类加载器限制
正如前面介绍的字节码操作工具,ASM、Javassit等可以对class进行操作修改,那是不是可以对一个已经加载的类进行修改并重载呢? 答案是不能。因为Classloader在加载类的时候会进行校验,对于已经加载过的类是不允许重复加载的。那如果字节码增强技术只能用在加载之前的范围,那可以使用的范围就特别有限了,好在Java提供了Instrument技术,也称agent技术,让这些字节码工具能够在类加载后也能进行修改,给字节码技术带来了广阔的使用范围和应用空间。
详细介绍
下面分别对几个字节码增强技术进行分别的介绍。
APT
APT (Annotation Processing Tool) 注解处理工具是Java提供的在编译时针对源代码内注解暴露开放点,进行额外处理。在源代码编译成字节码的过程中,编译器会首先把Source Code解析成抽象语法树AST,最终再编译成字节码。在这个过程中,APT可以根据注解,来对AST语法树进行修改,从而实现最终字节码的修改。以Lombok为例,在整个编译过程中,当遇到属于Lombok的注解时,编译器就会执行Lombok的Handler来实现功能增强。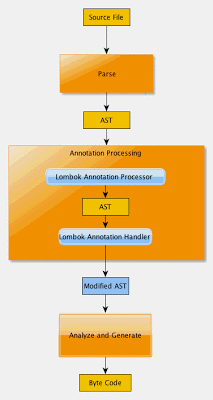
ASM、Javassit
ASM、Javassit以及CGLib都是针对是字节码的文件进行操作修改,这几个的区别已经在前文讲述,这里不再赘述,至于具体如何使用,不再本文范围内,有兴趣的可以参考此文:https://www.infoq.cn/article/kzmlUsizYFlw7F9t5jPO
Instrument
为支持字节码技术能对已加载的类进行操作,Java提供了JVMTI的接口,最常见的就是debug功能,其启动命令是:-agentlib:jdwp=transport=dt_socket,address=7085,server=y,suspend=n, 可以看到利用```agentlib``这个参数就能注入agent相关代码,从而进行插桩。
Agent技术提供了两种使用方式,一个是在启动的时候,正如前面的debug命令一样,在启动时添加agentlib参数,另一个则是在运行时动态attach的方式,通过 Attach API,将模块(jar 包)动态地 Attach 到指定进程 id 的 Java 进程内。为此,也提供了两个入口方法:
1 | public static void premain(String agentArgs, Instrumentation inst); |
分别对应两种不同的启动方式,当启动的时候,则调用premain方法,当运行中attach的时候,则是调用agentmain方法.
最早的agent lib实现方式都是采用Native方式实现,即c/c++的方式,这对于Java开发者来说门槛很高,为此,从Java 5之后,提供了java语言实现的方式,即大名鼎鼎的Instrument包,启动参数是: -javaagent,例如Aspectj动态方式的运行命令是:-javaagent:path/aspectjweaver.jar。
那么问题来了,JVMTI接口使用的是Native方式,那java是怎么运行JAVA语言实现的agent包呢?
这里用到了一个名叫instrument.so的动态链接库, 通过它我们实现了将JVMTI接口与instrument包的java接口得到了打通。即-javaagent命令相当于-agentlib:instrument。
重要知识
前面简单快速的介绍了Java字节码增强技术的概览,但作者在研究学习的时候,遇到了好几个重要的且令人疑惑的知识点,这里也进行一个重要阐述,与各位进行分享。
侵入/非侵入 v.s. 固化/非固化
使用agent技术的时候,我们常常说实现了非侵入的特性,但其实并不准确,我不使用agent技术,例如使用注解或者AOP等方式,也称作是非侵入的方式。从前面的介绍来看,显然agent技术的非侵入是与我们常说的非侵入不是一个概念了,为此,引出了一个固化与非固化的概念。
利用agent技术,agent携带的功能是可以随时加载或卸载的,也就是功能不是固化的,但类似AOP等方式,虽然是非侵入的,但具备的功能是早就固化了,不再能够卸载或者增加。
因此,我们可以细分下概念:
- 侵入: 引入的功能是否会侵入到业务代码里,讨论的对象是“业务代码”。
- 固化: 引入的功能是否可以动态的添加和卸载,是完全与运行的程序独立的,这里讨论的对象是“整个程序”。
Spring AOP v.s. Aspectj AOP
众所周知Spring AOP采用的是代理的模式,利用采用Java Dynamic Proxy或者CGLib的方式来实现,其原理是创建一个新的代理类来代理目标类,通过对代理类增加功能来实现AOP的切面。而Aspectj则有所不同,是直接通过修改目标类,在目标类里“织入”代码来实现切面。因此,这也是为什么Spring AOP会存在”Self Invocation”的问题,而Aspectj却存在的原因。
特别说明:
动态织入的AOP属于加载前还是加载后是有点模糊的地带,从AOP角度看,不管是用代理方式(Spring AOP)还是织入的方式(Aspectj Agent)都是属于加载程序之后了,但从字节码技术角度看,严格来说Spring AOP是属于加载前的技术,因为Spring AOP不管是JDK动态代理还是CGLib,都是生成一个新的代理类,并未修改原始的class,所以并不属于加载后阶段。
总结
本文以相对简短并快速的方式来简明扼要的介绍了字节码增强技术的相关知识,包括工具使用的所属阶段以及工具的分类,最后对侵入/非侵入,固化/非固化,Spring AOP,Aspectj AOP一些相对模糊的概念进行了重点讲解。